Transformerが万能ではない時もある。特に未来分析では。(「IISIA技術ブログ」Vol. 2)
鳴り物入りで再びAIブームとなっているわけだが、そうした流れをけん引しているのが大規模言語モデル(LLM)であり、アルゴリズムとしてはGPTだ。これに対して弊研究所がAIプロダクトとしご提供しているのは時系列分析(time-series analysis)の分野に属する金融指標ヴォラティリティ分析なのであって、そのために畳み込みニューラルネットワーク(CNN)とLSTMを実装しているということは前回のこのコラムで書いたとおりだ。そして現状を見る限り、後者は前者に比べてやや地味な感じのものとしてとらえられているように思うのは私だけだろうか。確かに一時、「AIロボヴァイザー」等と言って個人投資家に向け、後者のアルゴリズムをベースにしたサーヴィスの展開が我が国証券業界でもかなり流行ったことがある。だが率直にいうと、だからといって「儲かった!」と連呼してくれる個人投資家が続々と現れたわけではないわけである。今でもサーヴィス提供がなされている「AIロボヴァイザー」であるが、今や一世を風靡したといっても過言ではないChatGPTなど、「生成系AI」ともいわれる前者の流れと比べると正直、くすんでいるといっても過言ではないのかもしれない。
しかし、実はここにこそ今行われているAiを巡る議論の「落とし穴」があるように私には思えてならないのである。なぜならばGPTとLSTMは同根なのであって、根本においてそれらのアルゴリズムが「やっていること」は同じだからである(patern matching.この点は極めて重要なので別稿であらためて取り扱う)。そうした中で前者をベースにして発展を遂げる「言語生成系AI」はあたかもこれからの人類社会のすべてを制するのではないか、と言ったぐらいの勢いで喧伝されているのである。一部の良識あるAI研究のパイオニアが「そんなことはない!」と言ってもなお、そうした流れがマスメディアたちの中では止まらないことに空恐ろしさすら感じる。「生成系AIが人類を圧倒するなどということはあり得ないのだ」と言ったとたんに白い目で見られるような気がして恐ろしくなる。
端的にいうとここでの問題はこういうことだ。GPTとLSTMを比較すると、あたかも前者が後者を圧倒したかのように一般には語られ、「え?まだLSTMを使っているの?」と言われそうなのが今の現実である。しかしアルゴリズムそのものを単純に比較してその有用性についても結論を出すというのは余りにも乱暴な議論だと言わざるを得ないのだ。
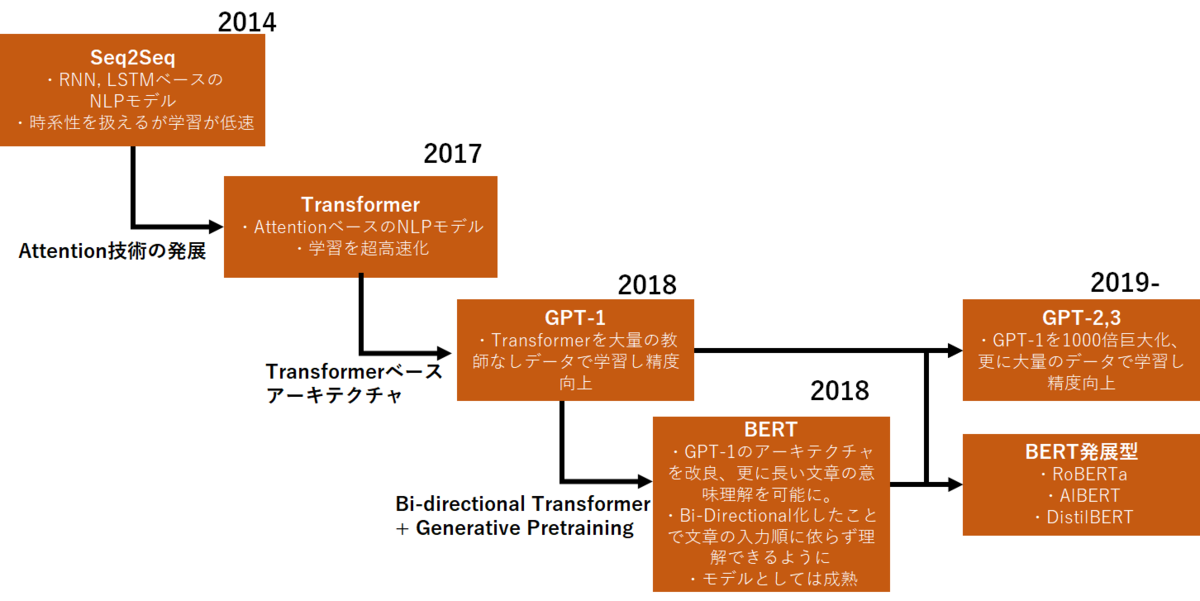
(Source: arutema47’s blog)
GPTの淵源を辿るとTransformerというアルゴリズムにたどり着き、そしてこのTransformerはAttention(注意機構)の発見・発明から始まっているものの、その実、RNN(再帰型ニューラルネットワーク)の改良版に過ぎないこと。この決定的な事実をAIをまともに勉強した方ならば知っている。そしてRNN一族とでもいうべき一連のアルゴリズムは、要するに「直近の入力値について行った損失関数の微分の結果を覚えており、今目の前で課題である同様の計算に際して参考にする」という点に共通の特徴がある。Attention(注意機構)とはそうして形成されたアルゴリズムの中でもどの部分に注視(pay attention)をすれば良いのかという点に絞り込んだものである。その結果、自然言語の連なりについてある単語を入力されると、その次に出てくる単語をより的確に推測できるようになった(だからGoogle翻訳は2017年頃から飛躍的に高性能になったのである)。
しかし、である。このことは要するにある意味、現実に入力された値に対する「過学習(overfitting)」がそれ以降のアルゴリズムでは当然視されているということをも意味するのである。自然言語において文章内の単語の流れを推測する場合にはそれでも良いのだ。なぜならばそこには時系列分析でいうような「トレンドとノイズの問題」が無いのであるから。Aという単語の後に続くBという別の単語のオプションは無限大にあるように見えて、文脈全体とのfittingを考えるとそうではない場合が多い。例えば「夕食の話」をしていて、いきなり「人類の終わりの話」をするということはほとんどないだろう。したがって自ずから狭められた言語空間で「◎」「×」ゲームをすればよいのであり、それが言語生成系AIの実態というべきなのである(しかも、大規模言語モデル(LLM)については「不適切な政治・差別表現がないように」という名目の下、最後はヒトが修正していることが公然と認められている。これでも果たして「万能のAI」なのだろうか?
それではTransformerで弊研究所のPrometheusの様なツールをつくろうとするとどうなるのだろうか。端的に言うと「大きな期待はものの見事に裏切られる」ことになる。実際、筆者もPrometheusのPOCにおいて並列してTransformerベースのコーディングも試してみたが、金融ヴォラティリティの未来予測という観点では全くもって使い物にならなかった。簡単に言うと「遊び」が少なすぎ、要するに「汎化(generalization)」に問題があったというわけなのである。極めてギザギザなチャートで示される値の連続が出てきてしまい、ヒトの能力を拡張する(augument)ためのツールとしては使い物にならないという印象であった。何せ、そもそも時系列データそのものがその時系列そのものに固有なトレンドと共に、ヒトの手が加わった「ノイズ」を構造的に抱えているのである。後者を前処理によって削ったところで、現実との比較という最後の段階で必ず「ノイズ」の問題が出てくる。そうなると、Transformerばりに「過学習」気味のアルゴリズムにしてしまうと全くもって現場では使い物にならなくなるというわけなのだ。
印象としては最近では自然言語処理ですっかり語られなくなったトピック・モデル(Topic Modelling)においてこの数年、話題になり続けていた構造的トピック・モデル(Structural Topic Model)がもたらした効果のようなものであろうか、上述の事情は。構造的トピック・モデルでは時系列という軸を巧みに取り組むことで、自然言語ととりわけ社会的な事象に特有な時系列的な「解釈」を可能にしたため、多くの社会科学者たちが用いたことで知られている。要するに社会事象となると、最終的に観察者の「解釈の余地」が無ければなかなかフィットしない結論しか出てこないということがあり得るわけだ。もっというならば「解釈者」としての立ち位置を許してくれる構造的トピック・モデルは「ヒトにやさしく」、AIの登場で「メシの食い上げになる」と考えていた多くの社会科学者に福音をもたらしたのである。
CNN+LSTM(さらにはMCMC)というシンプルな構成をPrometheusで用いているのはこうした事情による。やはり最後は「ヒトの手・目・頭脳」なのである。AIは単独で存立することは出来ない。そこには必ずヒトによる「意味付け」が必要だ。ChatGPTに代表される「言語生成系AI」がそこで出されるAIによる回答の「人間らしさ」を強調すればするほど、ヒトの世界とは実のところむしろ厳密さではなく、適度なファジーさがないと、最終的に本当の意味での正確さにはたどり着かないのである。それがAIを巡る現実なのだ。
2023年8月10日
東京・丸の内にて
原田武夫記す
(株式会社原田武夫国際戦略情報研究所 代表取締役CEO/グローバルAIストラテジスト)





