機械学習を1から学びたい方へ(クスノキ・プロジェクトへの招待 Vol. 22)
こんにちは。インターン生の中村友南です。
最近よく「機械学習」という言葉を見かけますが、実際には「何をしているのか、いまひとつ分からない」と感じる方も多いのではないでしょうか。
正直なところ、筆者自身も最初はよく分かりませんでした。そんな方にもきっと理解していただけるはずです。
この記事では、
機械学習の全体像 → 分類と回帰の違い → 活用例を整理します。さらに、前回に引き続き、実際にPythonを動かしてみます。
Pythonの動かし方については、前回ブログ:実践編―30分でPythonを触ってみる(クスノキ・プロジェクトへの招待 Vol. 21)にて詳しく解説しています! ぜひ、あわせてご覧ください。
3月29日(日)開催「クスノキプロジェクト第1弾ワークショップ」まで、残り1か月。
当日に向けて、基礎から理解を深めていきましょう。
さて・・・
機械学習とはシンプルに言うと、
これまでのデータからルールや傾向を学び、
次はどうなりそうかを予測・判断する仕組みです。
私たち人間も日常的に、
「今までこうだったから、次もこうなるかな」と予測しています。
機械学習は、そうした判断をコンピュータに行ってもらう方法だと考えると、少し身近に感じられるかもしれません。
なお、機械学習は「AI(人工知能)」と同じ意味で使われることもありますが、正確には少し異なります。
AIは人間のように考えたり判断したりする仕組み全体を指す大きな概念であり、その中核技術の一つが機械学習です。
機械学習にはさまざまな種類がありますが、特に基本となるのが次の2つです。
- 分類(Classification)
- 回帰(Regression)
分類は、あらかじめ決められたカテゴリの中からどれに当てはまるかを予測する手法です。たとえば「合格か不合格か」のように、結果がいくつかの選択肢のどれかになる問題がこれにあたります。
一方、回帰は数値そのものを予測する手法です。「売上はいくらになるか」のように、具体的な数値を見積もる問題が回帰です。
どちらもデータから学習する点は共通していますが、答えの形が「カテゴリ」か「数値」かという違いがあるのです。
今回はこのうちの「分類」を深堀しつつ、実際にpythonで分類を体験してみます。
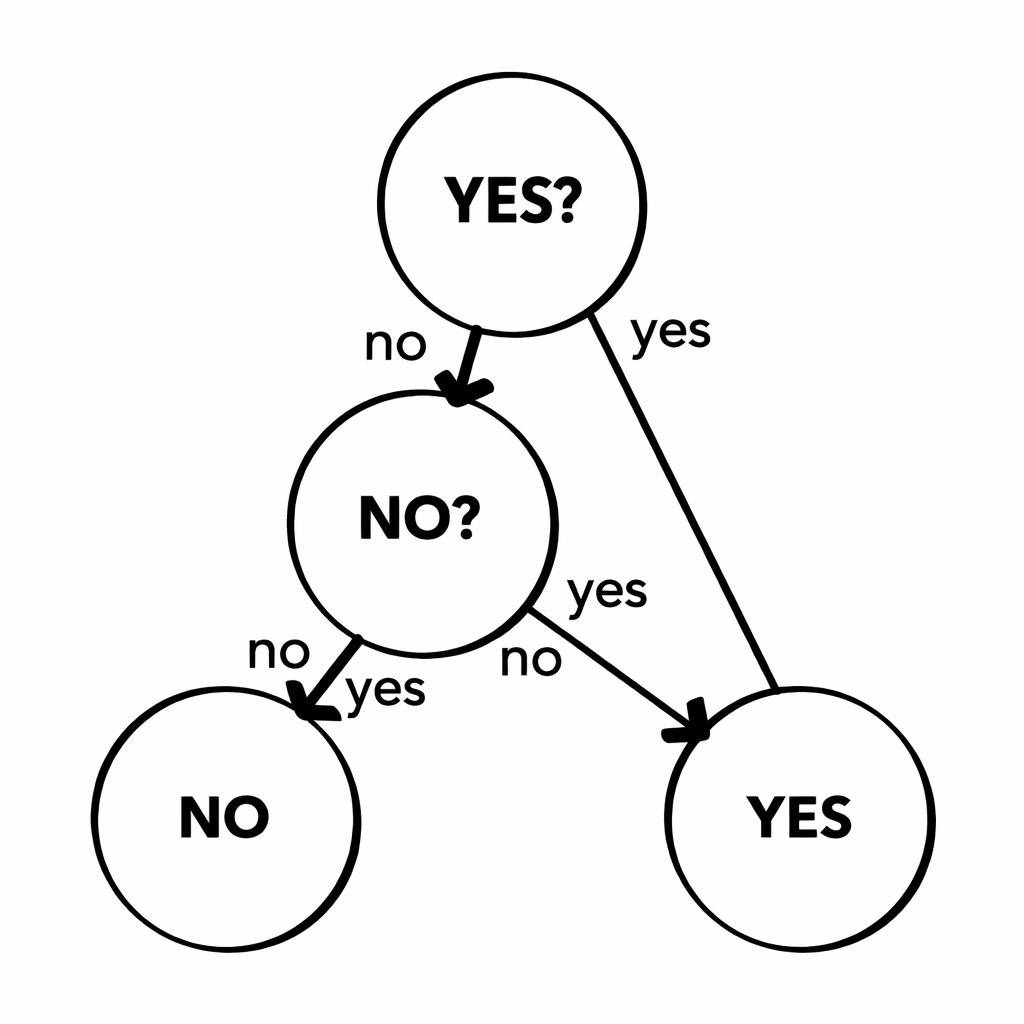
[分類のイメージ]
分類は、与えられたデータをあらかじめ定義されたカテゴリ(Yes、Noのような)に分けることを指します。結果は 決まった選択肢の中のどれかになります。
具体例としては以下のようなものが挙げられます。
- その学生は合格か不合格か
- 顧客は「購入する」か「購入しない」か
- 学生の成績評価(S,A,B,C…)は何か
つまり、
- YES / NO
- A / B / C
のように、ラベルが決まっている問題が分類です。
それでは、実際にPythonで分類を体験していきます。画像のコードをそのまま貼り付けてみるなどして、ぜひ一緒に手を動かしてみましょう!
今回はとてもシンプルなビジネス例を使います。
「過去の購入回数から、次にその顧客が購入するかどうかを予測する」という問題です。
Step1:ライブラリを読み込む
まずは、次のコードをそのまま貼り付けて実行してください。
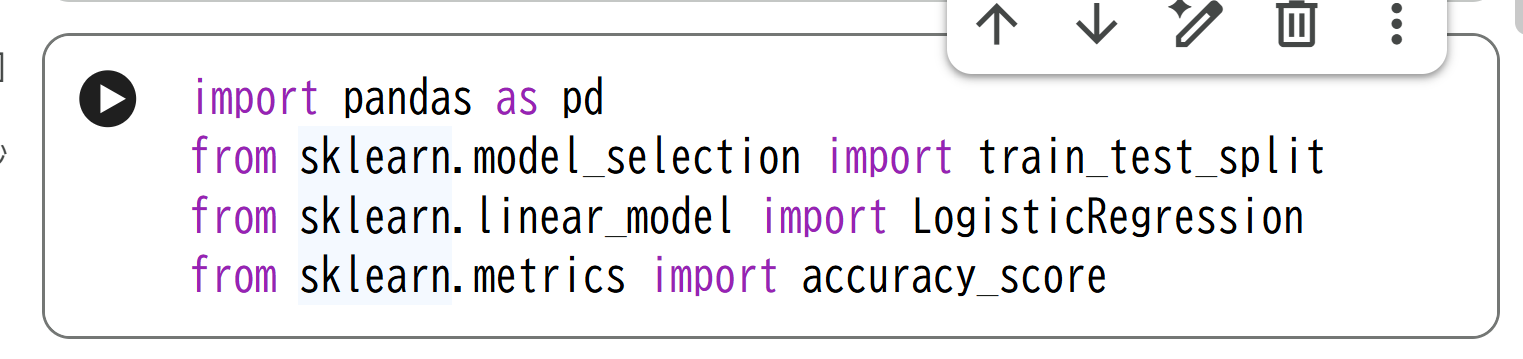
このコードは、分類を行うために必要な道具を準備しています。
内容を細かく理解する必要はありません。一つの「テンプレート構文」と思って、まずは動かしてみましょう。
Step2:データを作る
次に、顧客データを作ります。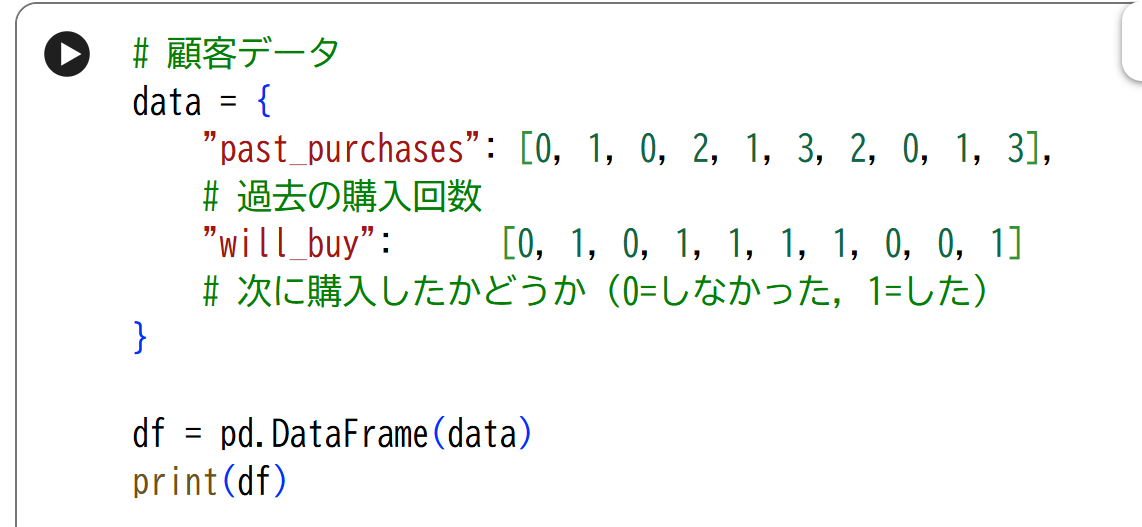
ここで作っているのは:
- past_purchases → 過去の購入回数
- will_buy → 次に購入したかどうか というデータです。この関係から、モデルにルールを見つけてもらいます。
Step3:学習用とテスト用に分ける

ここでは、
- 入力データ(購入回数)
- 正解データ(購入したか)
を分けたうえで、さらに
- 学習用データ
- テスト用データ に分割しています。
なぜ分けるのか?
―それは、モデルが「丸暗記」してしまわないようにするためです。
- 学習用 → ルールを覚える
- テスト用 → 本当に予測できるか確認する という役割があります。
Step4:モデルに学習させる

ここで、いよいよ学習が行われます。
モデルは、「購入回数がどのくらいなら、購入しやすいのか?」 という境界線を、自動で見つけます。
人間がルールを書く必要はありません。データから自動で学びます。
Step5:テストデータで予測してみる

学習したモデルを使って、「この顧客は購入しそうか?」を予測します。
0や1が表示されれば成功です。
Step6:正解率を確認する

ここで、どれくらい正しく予測できたかを確認します。
0.8 と表示されたら、80%正解という意味です。
今回のコードを実行すると、正解率はおよそ66%でした。
まったくのランダム(50%前後)よりは良いものの、まだ十分に高精度とは言えません。
ここから言えることは、もっと別の要素の情報を加えれば精度が上がる可能性がある
ということです。
いかがでしょうか?
とてもシンプルですが、実はこれがマーケティングや営業分析の基礎になっている考え方です。
データからルールを見つけ出し、判断を支援する仕組みです。
ぜひ今回のモデルを参考にして、他の問題にも挑戦してみてください!
次回ブログでは回帰モデルについて、整理し体験してみます。
このブログが面白いと思って頂けますならば、インターンシップの励みになります。ソーシャルメディア等で拡散して頂けると幸いです。
※当ブログの記述内容は弊研究所の公式見解ではなく、執筆者の個人的見解です。
株式会社原田武夫国際戦略情報研究所・インターン生 中村友南拝





