時系列分析とLLM。(「IISIA技術ブログ」Vol. 17)
以前明らかにしたとおり、弊研究所のAIデータサイエンス部門では現状、次の3つのテーマで研究開発を行っている。
―弊研究所がこれまで公表してきた調査分析レポートのテキストに基づくコーパスに基づく大規模言語モデル(LLM)の活用
―各種金融指標の時系列データに関する深層学習モデルによるトレンド分析の実施
―マルチエージェントモデルを活用した我が国を中心としたデフォルト(債務不履行)予測モデルの開発
1番目のものは現状、着実に開発を進めており、来年(2025年)1月にリリースする予定だ。名付けて知恵の神である「Minerva」シリーズであり、現在はより発展したコーディングが終了する中、WEBアプリとしての実装と共に高度なプロンプトエンジニアリングを試みている。次に2番目のものはこのコラムでもしばしば言及してきた「Prometheus」シリーズである。これについては各種金融指標に基づくトレンド分析のためのPrometheus I、さらにはこれにマルコフ連鎖モンテカルロ法に基づく事前関数と事後関数の推定を付け加えたPrometheus IIをリリース済みである中、来る7月20日の「2024年夏・IISIAセミナー」を契機として日本国債10年物及び米国債10年物のCDS(Credit default Swap)の保険料の時系列データを用いたトレンド分析を対象としたPrometheu IIIを発売予定である。こちらについても現在、最終調整中であり実装の最中、一部の計算結果を公表し、その成果を披歴しつつある。
第3の分野(multi-agent model)については大規模言語モデル(LLM)を用いてという形で構想中だが、まだ具体的な方向性をアルゴリズムについて見いだせているわけではない。非常に重要なプロジェクトになるとは思うのだが、むしろ今は上記の2番目の分野、すなわち金融指標に関する時系列分析としてのトレンド分析を大規模言語モデル(LLM)を用いて行う方向性を模索するという新たなプロジェクトを着想し、こちらに専心しつつある。
大規模言語モデル(LLM)については確かに一時期のユーフォリア(euphoria)というべき喧伝が静まり始め、徐々に冷静な議論がアカデミアの世界においても支配的になりつつあるように感じている。アルゴリズムの原理上、大規模言語モデル(LLM)が「幻覚(hallucination)」を必然的に起こすことはもはや疑いようのない事実なのであって、このことを踏まえつつ、一方ではこの幻覚(hallucination)を極力抑え込みながら、チャットボットを利用したそれとの対話の中で望ましい答えを個々の局面で引き出すにはどうすべきなのかという点に研究が収斂しつつある。もっとも他方では幻覚(hallucination)にある種の創造性の萌芽を見出そうとする流れもあり得るのであって、この点については前回のこのコラムで述べたとおりである。そして前者の方向性はさらにロボティクスにこうしたチャットボットを搭載させて操作させてはどうかという流れにつながり、さらなる社会実装の方向性を模索される展開となっているわけだが、本稿ではこの方向性での研究については紙幅の都合上、省くことにしたい。
むしろ本稿で着目したいのがいわば大規模言語モデル(LLM)の研究開発とその社会実装に際し、「王道」とでもいうべき上記の様な流れの脇からではあるものの、徐々に周辺領域における大規模言語モデル(LLM)の活用についての議論が始まっている点なのである。その一つがここで取り上げたい時系列分析(time-series analysis)なのである。なぜこうした方向性が出て来るのかといえば、大規模言語モデル(LLM)というと自然言語処理(NLP)にそれが特化している様に聞こえるが、実のところ大規模言語モデル(LLM)の淵源は再帰型ニューラルネットワーク(RNN)以降の一連のアルゴリズムにあるのであって、AttentionからTransformerへとつながる流れの中で特に言語処理との親和性に研究者たちが気づき、言語データとしてのコーパスを用いた学習とそれに伴う推論に特化する形で鍛え上げる中、開発してきたのが大規模言語モデル(LLM)であるにすぎないのである。他方で下記の図1からもわかるとおり、再帰型ニューラルネットワークこそ、そこから発展したLSTM以降の流れの中で時系列分析のいわば「王道」の地位を占めてきたアルゴリズムなのであって、だからこそいわば同根というべき大規模言語モデル(LLM)を時系列分析(time-series analysis)でも用いてみようという研究の方向性が出て来るのはいわば必然とでもいうべき流れなのである。
[図1 時系列分析(time-series analysis)のパラダイムシフト]
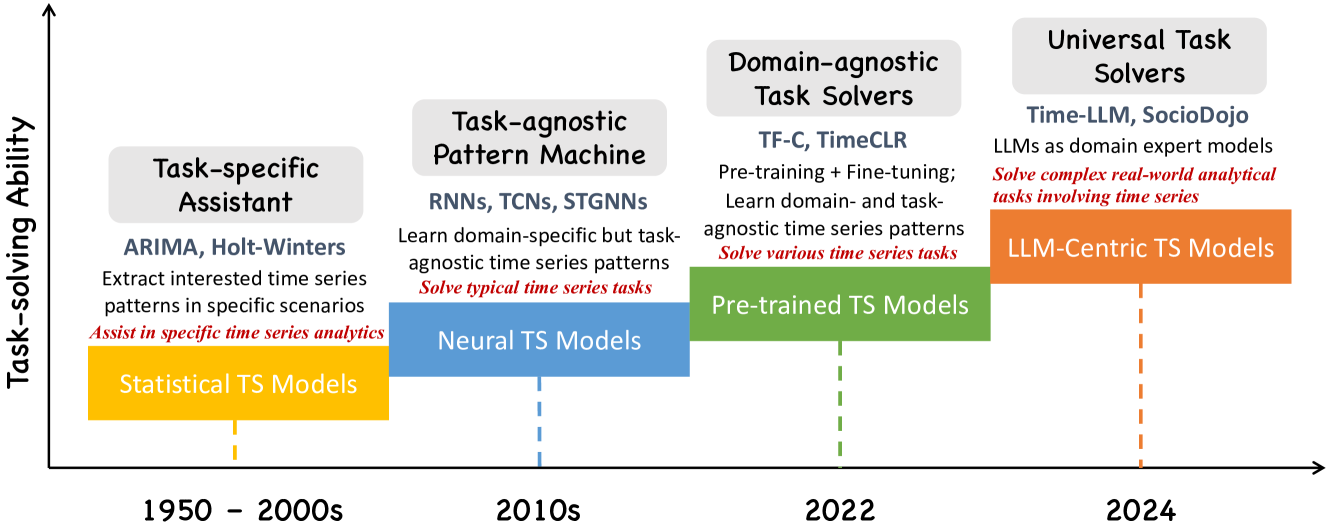
[出店:[Jin et al. 24]]
以上の様な「流れ」は流れとして理解するとして、それでは大規模言語モデル(LLM)を時系列分析に用いるとすると、どの様なメリットがもたらされるものと想定出来るのであろうか。この点について[Jin et al. 24]は次のとおり述べている。
…we believe that the field of time series analysis research is undergoing an exciting transformative moment. Our standpoint is that LLMs can serve as the central hub for understanding and advancing time series analysis. Specifically, we present key insights that LLMs can profoundly impact time series analysis in three fundamental ways: (19 as effective data and model enhancers, augmenting time series data and existing approaches with enhanced extrenal knowledge and analytical prowess; (2) as superior preditors, utilizing their extensive internal knowledge and emerging reasoning abilities to benefit a range of prediction tasks; and (3) as next-generation agents, transcending conventional roles to actively engage in and transform time series analysis. We advocate attention to related research and efforts, moving towards more universal intelligence systems for genral-purpose time series analysis.
この様に大いなる可能性を秘めている大規模言語モデル(LLM)を用いた時系列分析(time-series analysis)であるが、そのアルゴリズムそのものをもって演算を行うということになってくると大規模言語モデル(LLM)のパラメータ自身にアクセスが出来るかどうか、すなわち「ブラックボックス」とでもいうべき慫慂モデルかどうかがまず問題になってくると[Jin et al. 24]は述べている。もっとも仮に大規模言語モデル(LLM)のパラメータそのものについて修正を施した場合、壊滅的忘却(catastrophic forgetting)が生じかねない点に留意する必要がある。これに対してチューニングをしないのであれば時系列データを前処理して大規模言語モデル(LLM)の入力空間に対して如何に合わせていくのかが最大の焦点となってくるわけだが、この場合、大規模言語モデル(LLM)のトークナイザーは数値用に設計されていないため、連続値を分離し、時間的な関係を無視してしまうという致命的な問題点があり得る。
よってこれら両方の課題を解決すべく、[Jin et al. 24]は大規模言語モデル(LLM)を汎用的な時系列分析や問題解決のためのエージェントとして直接活用する研究の方向性を紹介している。同論文では基本的な時系列分析の実行をサポートするように大規模言語モデル(LLM)にプロンプトを与える実験を行った際の結果を取り上げている。それによるとそうした活用の方向性は見いだせるものの、やはり「幻覚(hallucination)」は現状避けられないとして、次の様な実験結果例を示していることが興味深い。
[図2 大規模言語モデル(LLM)を時系列分析(time-serie analysis)のエージェントとして用いた場合のやり取りの例]

[出典:[Jin et al. 24]]
以上見てきたとおり、大規模言語モデル(LLM)を用いた時系列分析(time-series analysis)はグローバル社会全体を見ても未だ研究開発の途上にある。ちなみにMeta社はLag-Llamaなるオープンソースモデルを出している[Rasul et al. 23]が、これは大規模言語モデル(LLM)ではなく、多数の時系列データで学習させた時系列予測のためのモデルである。確率的予測(probabilistic forecasting)を行うためのモデルであるが、厳密な意味で大規模言語モデル(LLM)を用いたものではない点に留意する必要がある。
弊研究所ではかくなるグローバルトレンドの真っ只中にあって引き続き大規模言語モデル(LLM)を用いた時系列分析の可能性、さらにはPrometheus IV開発の可能性について模索して行く。
2024年5月16日 本郷・東京大学総合図書館にて
株式会社原田武夫国際戦略情報研究所 代表取締役CEO/グローバルAIストラテジスト
原田 武夫記す
(参考文献)
[Jin et al. 24] Jin, Ming, et al. “Position Paper: What Can Large Language Models Tell Us about Time Series Analysis.” arXiv preprint arXiv:2402.02713 (2024). [Rasul et al. 23] Rasul, Kashif, et al. “Lag-llama: Towards foundation models for time series forecasting.” arXiv preprint arXiv:2310.08278 (2023).




