ブラックスワンとPax Japonica:マルチエージェントの可能性(「IISIA技術ブログ」Vol. 10)
弊研究所が現在、人工知能(AI)分野で取り組んでいる課題は全部で4つある。次の4つである。
―時系列分析(time-series analysis)による金融マーケット分析
―大規模言語モデル(LLM)をベースとしたAIの外交分野における活用
―同じく大規模言語モデル(LLM)をベースとした国会答弁作成モデルの検証
―エージェント・モデルを用いたPax Japonicaの実現可能性を巡る検討
幅広くIT分野での研究というとこれにブロックチェーンを用いた自動売買アルゴリズムの開発とその実装が加わり、全部で5つの課題になるわけだが今回このことはあえてこれ以上触れないことにする。これらの課題については一方でアカデミアに対して提示していくための論文を作成し、対外公表すると共に、他方ではアルゴリズム開発を行い、社会実装で成果を上げていく所存である。既に年間2億円近くのビジネスを創り出してくれている金融指数に関する時系列分析アルゴリズムであるPrometheus I/IIがその最初の成果ということが出来ようが、弊研究所による研究・開発がこれに止まるものではないことは言うまでもない。この冬から来年(2024年)初夏頃までの研究計画は日程的にもかなりタイトなものになりつつある。
そうした中で今回はこれまであまり触れることのなかった最後の課題、すなわち「エージェント・モデルを用いたPax Japonicaの実現可能性を巡る検討」について概況と基本的な方向性について述べたいと思う。昨今、すっかり「大規模言語モデル(LLM)ないし拡散モデル(Diffusion models)による描画=人工知能(AI)」といった印象がマスメディアによって世論に対しばらまかれているわけだが、人工知能(AI)は決してこれらに限られるわけではない。とりわけマルチエージェント、あるいはエージェント・モデルについてはここに来て大いに注目され、研究開発が進められてきている分野であることをここではまず確認しておきたいと思う。
それではマルチエージェント、あるいはエージェント・モデルとはいったい何であり、またそれらはどういった効能を私たち人類に対してもたらすものなのであろうか。[和泉ら 17]は次のとおり概観している。
複雑な現象の分析、設計においては、従来とは異なり、対象となるシステムが所与のものと仮定することはできない。システム全体を表す法則が、システムを構成する要素の相互作用から創発しうるからである。われわれはこのような社会的・システム的課題について「マルチエージェント」の概念を用いることで新しい方法論が構築できると信じている。マルチエージェントとは、エージェントと呼ぶ内部状態と意思決定・問題解決能力、ならびに通信機能を備えた複数の主体によるボトムアップなモデル化を試みる。そしてこのインタラクションに基づく創発的な現象とシナリオを分析しようとする。
近年、マルチエージェントが注目されるようになった背景には、コンピュータそのものの急速な発展、オブジェクト指向などのソフトウェア開発手法の進歩、進化と学習を扱う人工知能技術の発展、分岐・相転移やカオス、自己組織化などを扱う非線形科学や複雑系科学の発展が挙げられる。そして、このような理論や手法を適用するためには、コンピュータによるシミュレーションによる理解が必要になる。
エージェント・モデルによる分析で大変興味深いのは、これを推進する研究者たちが明らかに「マクロ」と「ミクロ」の融合をそれによって試みようとしている点だ。社会モデルを構築する際、ミクロ主体の挙動は分かっても、マクロ全体とそれがどの様に結び付くのかが判然としない例は多々ある。この逆もまた然りである。またそうした試みの延長線上で、これまでの社会モデル分析においてしばしば目標とされてきたシミュレーションの実測値への近接化ではなく、むしろ「シミュレーション結果の不安定性によりたまたま生じた「一つでも面白い1本の軌道」を発見して、その軌道でのさまざまな「可能性」を分析するようなアプローチ」にこそ有効性を見出そうという議論が見られているのである[和泉ら 17]。この点について[和泉ら 17]はさらに掘り下げるかの様に次のとおり述べている。
[和泉ら 17]はここでいう可能世界ブラウザがどの様な意味を持つのかについて、さらに次の様にも述べている。この(中略)段階では、いつまでも現実のデータにシミュレーションを合わせることだけに固執するのではなく、過去データにない新しいエピソードを発見するためにエージェントシミュレーションを活用するという立場である。その一つの例として、「可能世界ブラウザ」という、構成論的なアプローチに基づくエージェントベースの社会シミュレーション研究の方法論が提唱されている。可能世界ブラウザでは、実データに基づきモデルを構築し(中略)、シミュレーションによりユーザが興味あるエピソードを作成する(中略)。そして作成したエピソードに関して、モデルの内部で何が起きていたのかを分析して、そのメカニズムを知る。
エージェントシミュレーションならば、実世界では百万回に1回のみ発生するようなブラックスワン現象を、何千・何万回も発生させることが可能である。そして、仮想世界で生じたブラックスワン現象のデータを解析することにより、ブラックスワンを事前に見ることができる。これによってブラックスワンの原因がどこから生じる可能性があるのか、ブラックスワンが起きたときにどのような対応を行えばその後の状況が変わるのかを論じることができる。このように、可能世界ブラウザによって、ブラックスワンに対応する社会経済システムのデザインができないだろうか。そして、「想定外のリスク」を想定することで、社会経済システムの安全性や信頼性の向上が期待できる。
熱心な読者であれば既にお分かりであろうが、筆者がマルチエージェントに強い関心を寄せているのは、弊研究所のヴィジョンであるPax Japonicaとこれが深い関係性を持ち得るからである。すなわち、Pax Japonicaという状況が生じるためにはどの様な出来事が起きることが必要であり、かつ重要であるのかを考察するにあたっては、これが既に起きたことではない以上、関連データは全て人工知能(AI)にとって「外挿」にならざるを得ず、予測は出来ないというべきなのだ。しかし、マルチエージェントを用いて分析をすることにより、「万が一にも」生じる事態がそこで仮想現実でありながらあらかじめ描出される可能性があり、そのことを可能世界ブラウザと呼ぶのかどうかは別としつつも、ブラックスワンとしてとらえ、その背後において実質的な原因をあらかじめ探ることにより、Pax Japonicaの実現を早めることも、また逆に遅くすることも可能になるかもしれないのである。
以上を前提にした場合、次に課題となってくるのが果たしてどの様にしてエージェント・システムの中で走り回り、そこであたかも「生きている個体」であるかの様に振る舞うエージェントたち個体のミクロ的な在り方を定義・設計し、かつそうした個体としてのエージェント同士の関わり合いをマクロ的なシステムにまで昇華する様、定義・設計するかという点なのだ。弊研究所でも実のところ半年ほど前から「エージェント・モデルによるPax Japonica実現性の研究」を課題としてきた経緯があるが、このモデル構築のところでこれまではたと立ち止まってきてしまった経緯がある。ミクロの部分であまりにも細かすぎてしまうとマクロでそれが反映されることになるのかが分からず、またマクロの部分で数多くの現実のデータを入れたところで、それによってミクロ主体が本当に動かされているのかと言うと全くそうではないこともあり得るのだ。そうした中でこの課題についての考察がしばし止まってしまっていたことをここで吐露しておきたい。
そうした中で今年(2023年)8月になり、[Park et al. 23]の論文が世に問われ、耳目を集めた。タイトルは”Generative Agents: Interactive Simulacra of Human Behavior”という論文である。この論文では我が国ではあまり馴染の無いヴィデオ・ゲームであるThe Simsをヒントに25体のエージェントがオンライン上でまずは設定される。極めて単純に言うならばChatGPTの中でもGPT-3 Turboを用いることでこれらエージェント同士の会話は記録され、エージェント同士の会話が進めば進むほどそのやり取りという意味でのデータはLLMであるGPT-E Turboに記憶(record)される中、人工社会(arifitificial society)あたかも生身の人間同士の社会であるかの様に発展していくというわけなのである。[Park et al. 23]は次の様に述べる。
In sum, this paper makes the following contributions:
・Generative agents, believable simulacra of human behavior that are dynamicallyu conditoned on agents’ changing experiences and environment
・A novel architecture that makes it possible for generative agents to remember, retrieve, reflect, interact with other agents, and plan through dynamically evolving circumstances. The architecture leverages the powerful prompting capabilities of large language models and supplements those capabilities to support long-term agent coherence, the ability to manage dynamically evolving memory, and recursively produce higher-level reflections.
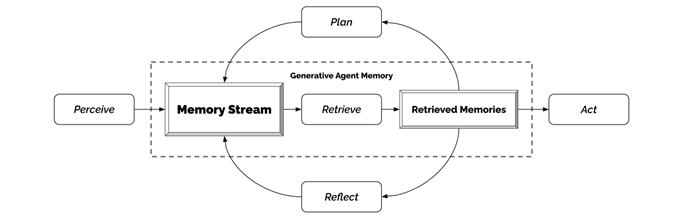

このマルチエージェントの中で決定的な意味合いを持つのがMemory Stream(上図参照)である。そしてここにこそChatGPTが実装されていることを[Park et al. 23]は次のとおり述べる。
At the center of our architecture is the memory stream, a database that maintains a comprehensive record of an agent’s expericence. From the memory stream, recoards are retrived as relevant to plan the agent’s actions and react appropriately to eht environment. Records are recursively synthesized into higher- and higher-level reflections that guide behavior. Everything in the architecture is recorded and reasoned over as a natural language description, allowing the architecture to leverage a large language model.
Our current implementation utilizes the gpt3.5-turbo version of ChatGPT. We expect that the architectural basics of generative agents-memory, planning, and reflection-will likely remain the same as language models improve.
細かなことは別稿に譲ることとしたいが、要するにChatGPTを用いてエージェント同士の会話を記録し、さらには新たな対話のため既に記録された会話という意味でのデータを引き出す(retrieve)ことにより、次々にエージェントたちが新しい振る舞いを相互作用の中でしていくというわけなのだ。例えば[Park et al. 23]は「ヴァレンタインデー」を例に次の様な所作がエージェント同士の間で見られたと報告する。
For example, starting with only a single user-specified notion that one agent wants to throw a Valentine’s Day party, the agents autonomously spread invitations to the party over the next two days, make new acquiainstances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time.
ここで述べるのはあくまでも「ヴァレンタインデー」といった軽い事例であるが、筆者はこの様にLLMを利用したエージェント・モデルの構築を通じて、より複雑な社会モデル、端的に言うならば我が国のミクロ環境とマクロ実態とをつなぐモデル構築が可能ではないかと考えており、その先においてPax Japonicaが実現するとすればどの様な事態の発生が必要なのかといった考察が可能なのではないかと考えている。いや、もっと端的に言うならば(上述のブラックスワンという響きにより適合的な課題として)「日本デフォルト(Japan’s Default)」の研究も可能なのではないだろうか。そうすることで伝統的な考え方で言うならば「動的開放モデル」を単なる数理分析・統計分析の延長線上ではなく、むしろ「自然言語処理(NLP)」を用いた対話分析の延長線上で描き出せるのではないかと考える次第である。
まだまだ生煮えの段階のアイデアではあるが、最新の論文にinspireされたということで覚書的にここでは記しておくことにする。来年(2024年)内には、現実がまだ完全には進行しきらない間にLLMを用いた「Pax Japonicaモデル」の初期的な構築を成功にまで導きたいと考えている。
2023年11月19日 東京・丸の内にて
株式会社原田武夫国際戦略情報研究所 代表取締役CEO/グローバルAIストラテジスト
原田 武夫記す
(参考文献)
[和泉ら 17]和泉潔、斎藤正也、山田健太:マルチエージェントのためのデータ解析(2017) [Park et al. 23]Park, Joon Sung, et al. “Generative agents: Interactive simulacra of human behavior.” arXiv preprint arXiv:2304.03442 (2023).




