「AIと金融」その最前線を知る。(「IISIA技術ブログ」Vol. 18)
一般社団法人人工知能学会全国大会(第38回)が今般、浜松アクトシティで開催されたが、内28~30日について正会員かつ研究発表者の一人として出席してきた。筆者自身の研究発表については既に概要をリリースしたので、今回は別の確度から今回の全国大会について考察したことに関し、小文を寄せられればと思う。
筆者自身の研究発表はアカデミアにおける研究テーマとしてきている「AIと外交」に連なる主題であったが、他方において今回の全国大会出席にあたってはもう一つの目的があった。それは弊研究所における研究開発テーマの一つである「AIと金融」について、我が国における研究の最前線を知ることである。関連するセッションは複数行われており、そのすべてを網羅することは日程的に不可能であったが、それなりにこの点に関する「我が国の現在位置」をつかめた印象を受けている。
「AIと金融」を巡る研究方向は平たく言うと4象限に分かれている。まず第1の軸が「時系列分析(time-series analysis)」なのか、あるいは「自然言語処理(natura language process)」なのかという軸である。これに対して第2の軸が「分類(classification)を前提とした最適化(optimization)」なのか、あるいは端的に「予測(prediction)」なのかである。弊研究所ではこれらの内、既に2つの機種をリリース済である「Prometheusシリーズ」において「時系列分析」×「予測」の象限に入る部分にコミットしてきている。しかし実のところこの組み合わせこそ、実需がありそうであるものの、少数派の研究対象なのであって、むしろ「自然言語処理(text mining)」×「分類・最適化」が主流であることを垣間見た次第である。
アルゴリズムとしては一つに新種のオルタナティヴ・データ(alternative data)をどの様に既存のアルゴリズムに入れるのかという点について、テキストデータからコーパスをつくり、これをベクトル化させるというオーソドックスなものが主体であったように感じている。さらに言うとトピックス・モデル(topic modelling)やワードクラウド(wordcloud)といった「往年のアルゴリズム」でも新たな研究発表が行われていることを現場で確認出来た。今回、人工知能学会金融情報学研究会(SIG-FIN)の懇親会にも出席する機会を得、若い世代の研究者たちの率直な見解を聞くことが出来たが、そこでも「株価予測そのものをまずは志す学生が多いが、研究室の中で早々に『それはやめておきなさい』と言われるのが関の山である」といった声を複数人から聞くことが出来た。しかし、「金融とAI」という分野は結局のところ、未来予測(future prediction)に尽きるというのが卑見である。すなわち人工知能(AI)には過去データとのパターンマッチングでしかない以上、「内挿」でしかないのであって、よってそこに含まれていない将来の株価を予測すること(=外挿)は範疇外であるということを踏まえても、「それでもなお」と新たな方向性を考えることこそがそこでのミッション(使命)なのである。しかしおよそ今回の全国大会でもそうした方向性での議論はほぼ見られなかったのが遺憾ではあった。
これは一つにはそもそも若き「AIと金融」関係者が、マーケットの分野で「身銭を切って投資をし、成功を収める」ことをもって生業とした経験が無い者ばかりであるということによっているように今回の全国大会の現場での出会いを通じても強く感じた次第である。金融の世界は要するに「いくら儲けたのか」というのが勝負所なのであって、「分類上の最適解」を過去データについて突き詰めてもおよそ有意性はないのである。しかし、これを忌避している背景には特定の大学の特定の研究室の現役大学院生あるいはOB・OGが我が国における「AIと金融」の分野では大きな影響力を持っており、かつそこでの研究テーマが師匠である教授の「テキストマイニング」を巡る研究に紐づけられていることにもよっている様に感じた。したがってこれら2つの要因から解放されたところに、むしろ我が国における「AIと金融」を巡る新しい息吹を感じることがあるいは可能なのではないかとの印象も覚えた次第である(弊研究所の「Prometheusシリーズ」の背後における研究は正にそうした問題意識に合致したものであることをここでは確認しておきたい)。
他方、こうした一連の動向の中で出色であったのが[中田 et al. 24]である。今大会の予稿集(同大会の参加者のみ現状では閲覧可。来る7月頃にJstageで公開される見込み)に掲載されている同論文には次の様な記載がなされている。
株式市場においては、景気循環の局面に応じて、物色される銘柄群に違いが出ると言われている。本研究では、株式市場の構成銘柄の売り物色の、長期的な景気循環に関係する銘柄群への偏りの度合いから、リスク指標値を算出する手法の開発を行った。具体的には、長期のリターンの相関係数行列から関係性の強い銘柄同士をクラスタリングして、短期間の物色が各クラスタ上で偏りが発生するかを、Graph Based Entropyと領域間相互作用の手法を用いて定量化した。TOPIX 500、S&P 500、STOXX Europe 600の3つの株式インデックスに対して、既存のリスク指標値(ボラティリティ、流動性、相関)との性質を比較した。開発した指標値は、既存指標値では反応しない局面で反応し、既存指標値では捉えられないリスクを検知できている可能性が示された。
この研究が提案するリスク指標値はこれまで種々提案されてきた指標値とは異なり、「先行指標」としての性格を持っていることが今回示された点が端的に言うと出色であったのであり、会場における討論でもその点に関する指摘があった。また具体的な手法に関しては次のとおり記載がある。
1 株式市場の構成銘柄に対して、長期(5年)の市場平均リターン(株式指数のリターンに対する超過リターン(日次)の相関係数行列からMacmahonら[Macmahon 15]が行ったランダム行列理論とLouvain法で、クラスタリングを行う
2 株式市場の構成銘柄を、以下2パターンで領域分けする。
売り物色:短期(20日)のリターン下位10%、その他(90%)
買い物色:短期(20日)のリターン上位10%、その他(90%)
3 1の長期クラスタと、2の短期領域から、Nishikawaら[Nishikawa 2022]の手法をもとに領域間相互作用を計算する。売り物色、買い物色の各々のパターンの領域間相互作用の差を基に、物色によるリスク指標値を算出する。
4 上記1~3を週次ごとに計算して、指標知の時系列データを算出してその性質を評価する
以上の作業の結果、長期物色のクラスタに、短期的な売り物色銘柄が偏っている場合、3で産出する指標値が高くなり、結果として投資家心理の景気後退の期待による物色が多いと判断でき、長期的に株価の果報リスクが高まる可能性がある、と[中田 et al. 24]は論じている。そして以上の様なリスク指標の計算にあたり、[中田 et al. 24]はネットワーク上のクラスターをエントロピーで表現し、構造的変化を定量的に評価するための手法だえるGraph-Based Entropyを用いる。
(図 物色によるリスク指標値(青)とS&P500指数(橙)の比較)
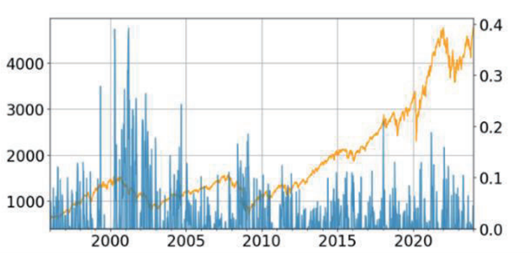
(出典 [中田 et al. 24])
上記の図で明らかなとおり、この研究で導かれるリスク指標値は株式指数に対する「先行指標」となっていると言える。すなわちこのリスク指標値が上がるとその後、当該株式指数は下落し、逆に前者が下がると後者は上がるという関係にあることが分かるのである。
この[中田 et al. 24]の提案する手法に今回、大いなる啓発を受けた次第である。「時系列分析」×「予測」の組み合わせに対する伝統的な深層学習に拘ることなく、こうした新しい角度からの切り込み方についても今後、大規模言語モデル(LLM)を用いた方向性の模索と共に「AIと金融」の分野で活発に研究を推し進め行きたいと考えている。
2024年6月1日 東京・丸の内にて
株式会社原田武夫国際戦略情報研究所 代表取締役CEO/グローバルAIストラテジスト
原田 武夫記す
(参考文献)
[中田 et al. 24] 中田喜之、吉野貴晶、杉江利章、夷藤翔、関口海良、劉乃嘉、大澤幸生: Graph-Based Entropyと領域間相互作用を用いた株式市場の異常検知、人工知能学会全国大会(第38回)予稿集、2014年. [Macmahon 15] MacMahon, Mel, and Diego Garlaschelli. “Community detection for correlation matrices.” arXiv preprint arXiv:1311.1924 (2013).




