テキスト生成系AIに対する評価指標を巡る覚書(「IISIA技術ブログ」Vol. 7)
相変わらず生成系AI(generative AI)を巡る議論が喧しい。もっとも一時の様なeuphorischな議論が横行しているかというとそうではなく、「生成系AIが何であるのかは大体分かった。それでは一体何に使えば良いのか?」といった、社会実装を巡る議論が徐々に浸透しつつある様に感じている。そうした中で弊研究所としては概ね次の様な社会実装を自ら目指すべきと考えている。
―大規模言語モデル(LLM)におけるいわゆるファインチューニング(fine tuning)に際し、これまで弊研究所が過去16年余にわたって日次でリリースしてきた「IISIAデイリー・レポート」のテキストを用い、学習させる(*そもそもこの段階で大規模言語モデル(LLM)そのものについて特に活性化関数(activation function)に関連し、いわゆる「四則和算」を用いた改良を施すという手があるが、これについて書きだすとendlessになる危険性があるので別稿に譲ることにする。)。
―生成系AIの中でも例えばChatGPTはオンライン上の他媒体との接続が出来るようになる旨、直近で表明している。すなわちこれにより、2022年以降のデータは学習されていないという「例の問題」は解消されるというわけなのである。よって例えば上記における大規模言語モデル(LLM)としてChatGPTを採用し、これに同上のファインチューニングを実施する。
―この結果、プロンプト(prompt)をコマンドとして用いることにより、「IISIAデイリー・レポート」を日次で自動生成させることが可能になる。通常、「IISIAデイリー・レポート」は単独執筆の場合、約1時間が費やされている。ChatGPTが執筆の部分を行えば時間はおそらく3分の1程度にまで圧縮できる可能性がある。当然、「幻覚(hullcinatoin)」があるのでチェックは必要ではあるが、相当な時間短縮である。
―さらにChatGPTに「IISIAデイリー・レポート」を作成させる場合、アナウンサー原稿の様に作成せよとすればその様な形で作成できる。これに静止画像をもって「ヒトがしゃべっているかの様に生成する」アプリを連携させれば、我がヴァーチャルPR担当「Mariko」はかなり詳細な分析を日々喋る様になることが出来る。さらにはホログラムやロボットを連携させることで、立体での表現も可能であり、弊研究所の”情報リテラシー”普及に対して一気に拍車がかかる。
さて。こうした形で「研究開発のイメージ」は広がる一方なのであるが、他方で気になるのが生成されたテキストに対する「評価指標(metrics)」の選択である。一般にはお手本=正解がないテキストが次々に生成される事実そのものにばかり注目が集まりがちだが、自然言語処理(NLP)のみならず、人工知能(AI)開発においてイロハのイになっているのがこの「評価指標(metrics)」に関する問題である。すなわちどこまで精緻な、かつ正解に近い文章が生成されたのかが本当の課題なのであって、「単語の順列」「意味」といった複雑な構成要素を持つ文章についてどこの角度から見ることで、生成された文章が「正解」にどれだけ近いと言えるのかを巡って、事実これまで多数の試みが行われてきたのである。現在、筆者は我が国外交の実務上、外交文書の要約がとりわけ若年層の外務省員にとって大きな作業負担になっていることに着目し、「外交文書の要約ツールとしての生成系AIの活用可能性」に関する論文執筆を行っている。その関連でここでいう「評価指標(metrics)」についても取り組んでいるので、その成果を少しだけ紹介したい。
生成系AIによって生成されたテキストと「正解」である文書との関係性を巡る問題、すなわちそれを巡る「評価指標」の問題は要するにテキスト間の類似度に関する課題である。[難波 2020]はこの課題を巡っての解法は「テキスト間の引用等の関係を利用する方法」と「テキスト中の単語を利用する方法」の2種類があり、とりわけ後者には下記のとおり複数の手法があるとしている。
―集合間の類似度を用いる手法
テキストAとテキストBに含まれる単語を、集合A及びBの要素と考え、Jaccard係数、Dice係数、Simpson係数といった集合間の類似度尺度を用いる手法。単純で分かりやすいものの、テキスト中でそれほど重要でない単語であっても非常に重要な単語であっても、全て等しく扱うため、適切な類似度が計算出来ない。
―コサイン類似度を用いる手法
まず基本的な統計量としてtf-idfを用いる。tfとはterm frequencyであり、idfとはiinverse document freqauencyである。tf-idfはこの2つの乗算として計算できる。すなわちtfはテキストA内における単語tの頻度を差す。これは「テキスト中で何度も繰り返し言及される概念は重要な概念である」という仮定に基づいている。またidfはN件のテキストが存在し、この中で単語tが出現するテキスト数がdf(t)である時、1+log(N/df(t))の値を指す。こうすることでどのテキストにも出現するような単語tはdf(t)の値がNに近づくため、idfは0に近い値となる。こうしたtf-idfを用いることで、一つのテキストからテキスト中の各単語とその重要度の対の集合を得ることが出来る。
そして各単語を軸とし、その単語の重要度をその軸の座標と考えることで、テキストは一つのベクトルとみなすことが出来る。そして異なるテキスト、例えばテキストAとテキストBのベクトルについて内積を計算する。テキストAとテキストBの内容が似ている時、同じ単語が近い確率で各テキスト中に出現すると考えられるため、そこで求められるcosθは1に近づく。逆であれば0に近づく。このcosθを「コサイン類似度」と呼ぶ。
もっともこのコサイン類似度では、単語が異なっていても意味が類似している場合について、そうではない場合と区別するための類似度尺度とはなり得ない点に問題がある。
―単語の分散表現を用いる方法
「ある単語は、その周辺にどのような単語がどのような頻度で出現するのかという情報から、ある程度意味を表現することができる」ということ、また「テキスト集合中のすべての単語について、それらの周辺単語の情報を収集すれば、周辺単語の類似性によって、単語の意味を表すことが出来る」といういわゆる分布仮設に基づく。ニューラルネットの発展に伴って実用化の提案がなされるに至り、各単語の意味を数百次元のベクトルで表現することで2つの単語の意味的な類似性をコサイン距離を用いて計算することを可能にしただけではなく、意味的な演算も可能にした。その典型例がWrod2Vecである。そしてこのWord2Vecを用いたテキスト間の類似度尺度としてはSCDV、Paragraph Vector、SWEMなどが提案されてきた。
[難波 2022]は以上を紹介した上で最新の事例としてBERTScore[Zhang et al., 2020]を簡単に紹介するわけであるが、その前にこれまで頻用されてきた手法としてn-gramマッチングについて触れなければならない。BLEU[Papineni et al., 2002]やMETEOR[Banerjeee & Lavie, 2025]が典型であるがその問題点について[Zhang et al.,2020]は端的に次のとおり述べている。The most commonly used metrics for generation count the number of n-grams that occur in the reference x and candidate xˆ. The higher the n is, the more the metric is able to capture word order, but it also becomes more restrictive and constrained to the exact form of the reference.
n-gramでは連続するn個の単語がどれだけ一致しているのかに基づいて評価が下される。したがって生成された文章あるいは正解となる文章のどこが切り取られ、比較されたのかのよって評価結果に違いが出てしまうという致命的な問題があるというわけなのだ。
―BERTScoreを用いる方法
そこで開発されたのがTransformerをベースにGoogleが開発したBERT(Bidirectional Encorder Representation from Transformers)が提案する文脈上の埋め込み(contextual embeddings)を評価基準に用いるBERTScoreである。[Zhang et al., 2020]は冒頭のabstractにおいて次のとおり述べている。
We propose BERTScore, an automatic evaluation metric for text generation. Analogously to common metrics, BERTScore computes a similarity for each token in the candidate sentence with each token in the reference sentence. However, instead of exact matches, we compute token similarity using contextual embeddings. We evaluate using the outputs of 363 machine translation and image captioning systems. BERTScore correlates better with human judgements and provides stronger model selection performance than existing metrics. Finally, we use an adversarial paraphrase detection task to show that BERTScore is more robust to challenging examples when compared to existing metrics.
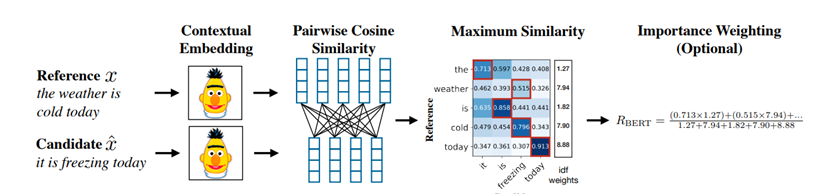
(Source: [Zhang et al., 2020])
すなわちBERTScoreでは、参照文と候補文に含まれるトークンをBERTによってまず文脈上の埋め込み(contextual embedding)が施され、それぞれベクトル表現に変換される。こうしてできた参照トークンと候補トークンを用いてトークン間のコサイン類似度を求める。さらに参照文と候補文の類似性を求めるにあたってはこのコサイン類似度が最大となるトークン同士をマッチングさせて制度を求めるわけだが、これに基づき適合率、再現率、F1スコアが定義される。さらにBERTScoreでは単語の重要度(Importance Weighing)を用いるべく、idf(inverse document frequency)を用いる。こうして仕組みを持つBERTSCoreは機械翻訳や画像キャプションについての比較を行う中で既存の他の評価指標よりも高性能であることが判明したと[Zhang et al., 2020]は結論づけている。
最後に。もはやde facto standardになったかの様な感のあるBERTScoreであるが、使い慣れていない者にとって以外に難しいのが様々なヴァージョンアップに伴うコーディングの変更だ。参考までに下記のとおり、実装に際して用いることの出来る、最も単純なコードを示しておくことにする。この様に示すと実に簡単で使いやすい。筆者も今後はこの評価指標に基づきつつ、考察を続けていくことにしたい。
https://trinket.io/python3/a276c3f28a
2023年9月30日 東京・丸の内にて
株式会社原田武夫国際戦略情報研究所 代表取締役・CEO
原田 武夫記す
(参考文献)
難波英嗣. “テキスト間の類似度の測定.” 情報の科学と技術 70.7 (2020): 373-375.
Zhang, Tianyi, et al. “Bertscore: Evaluating text generation with bert.” arXiv preprint arXiv:1904.09675 (2019).





